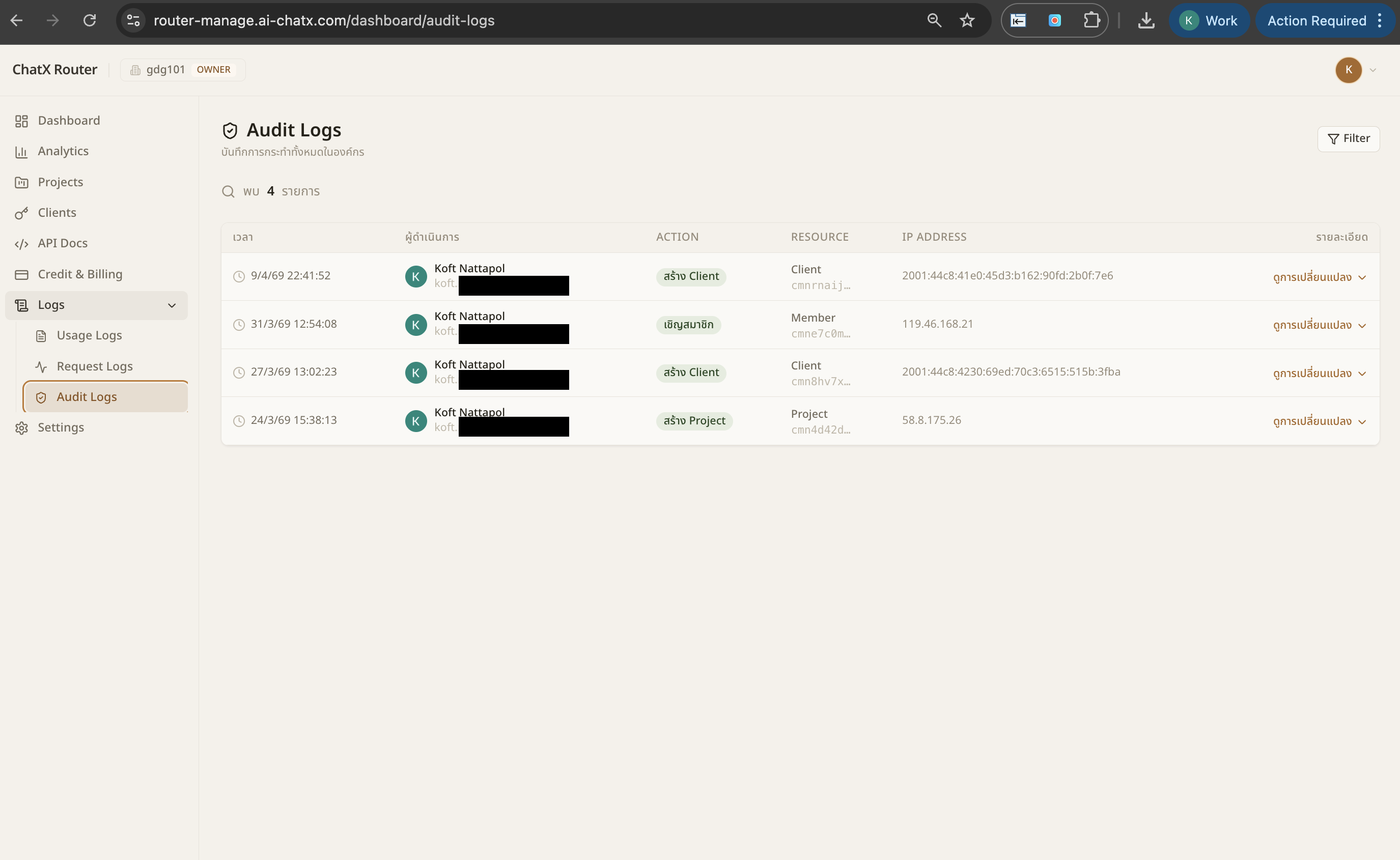
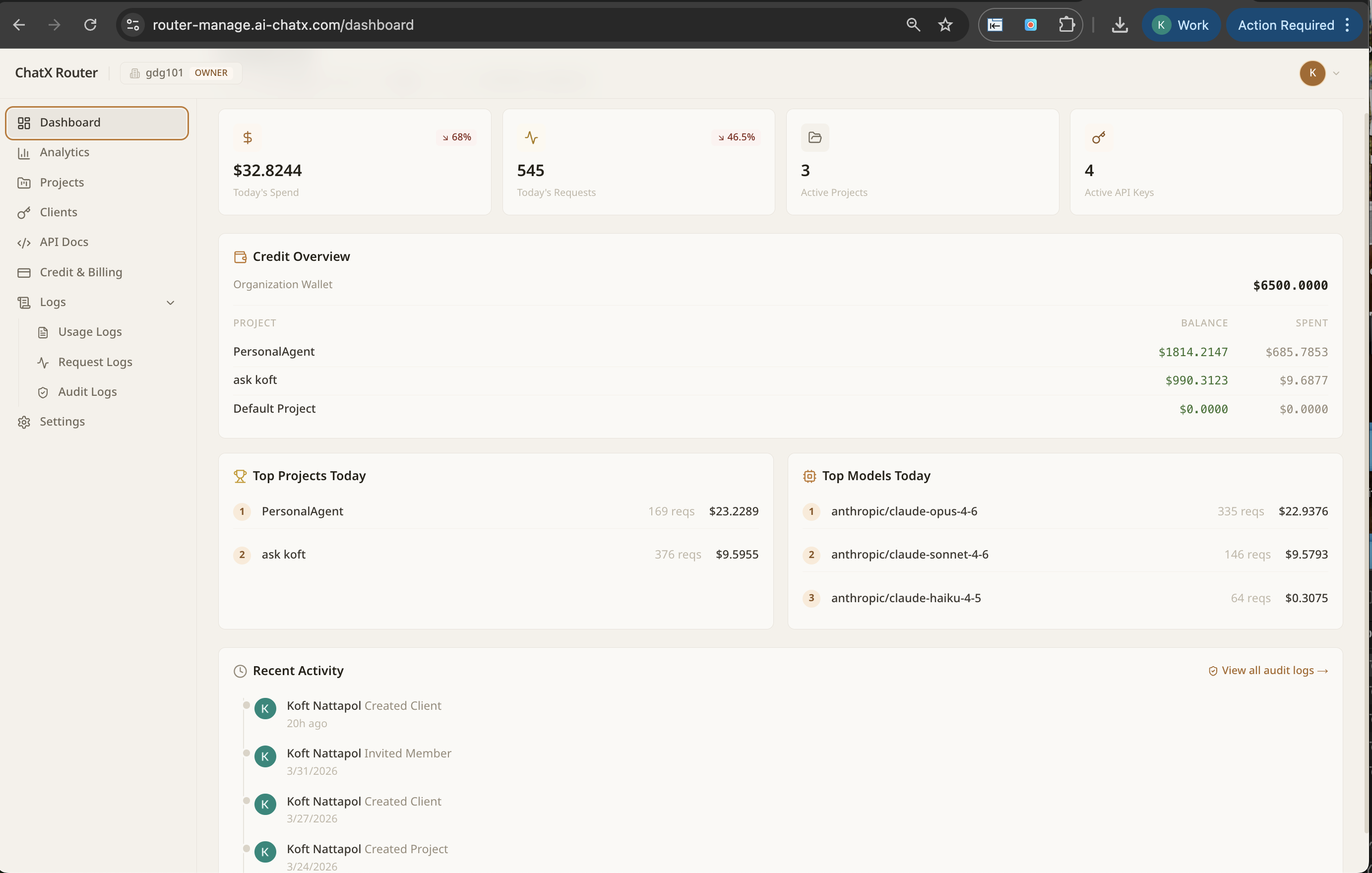
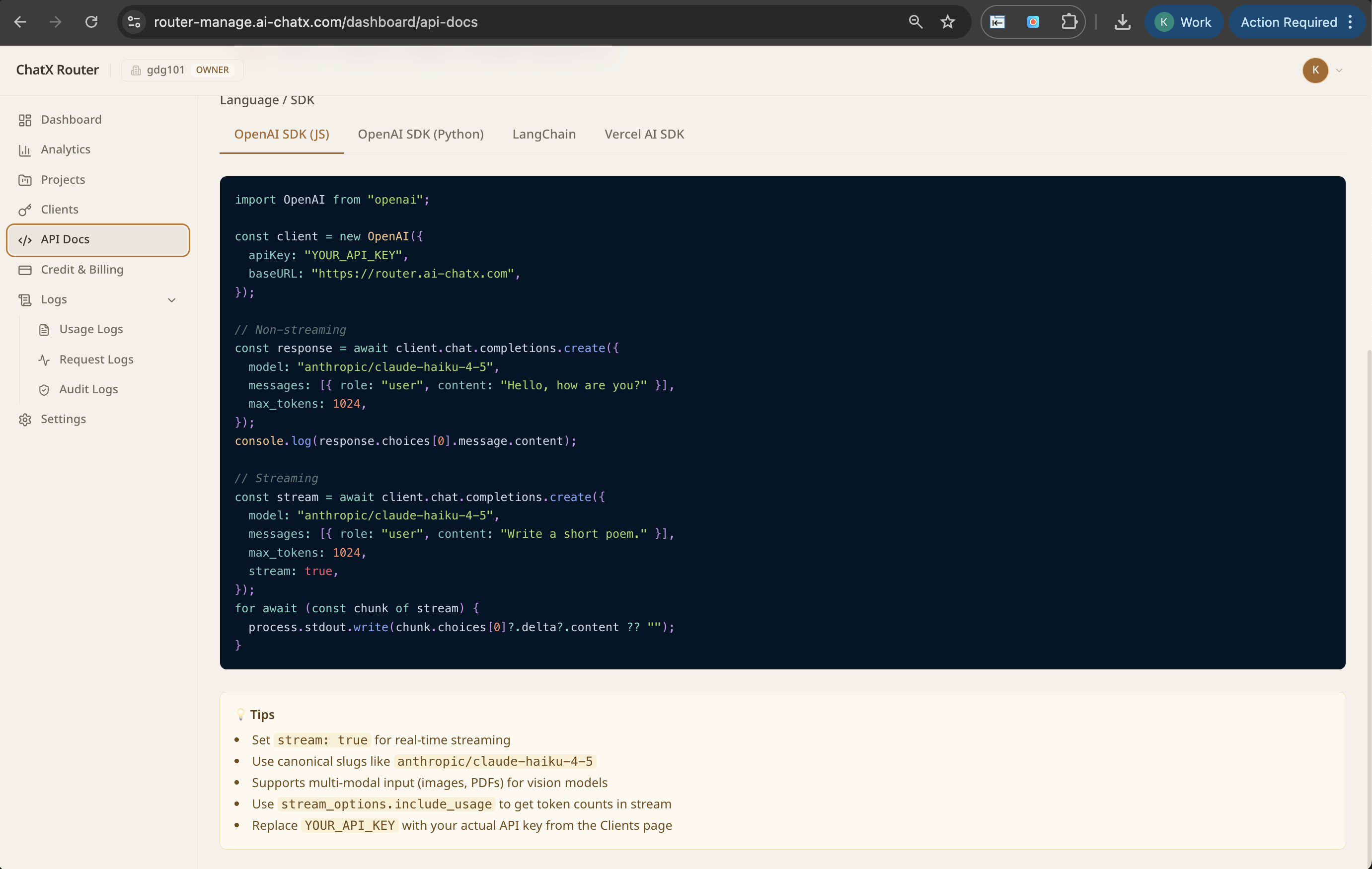
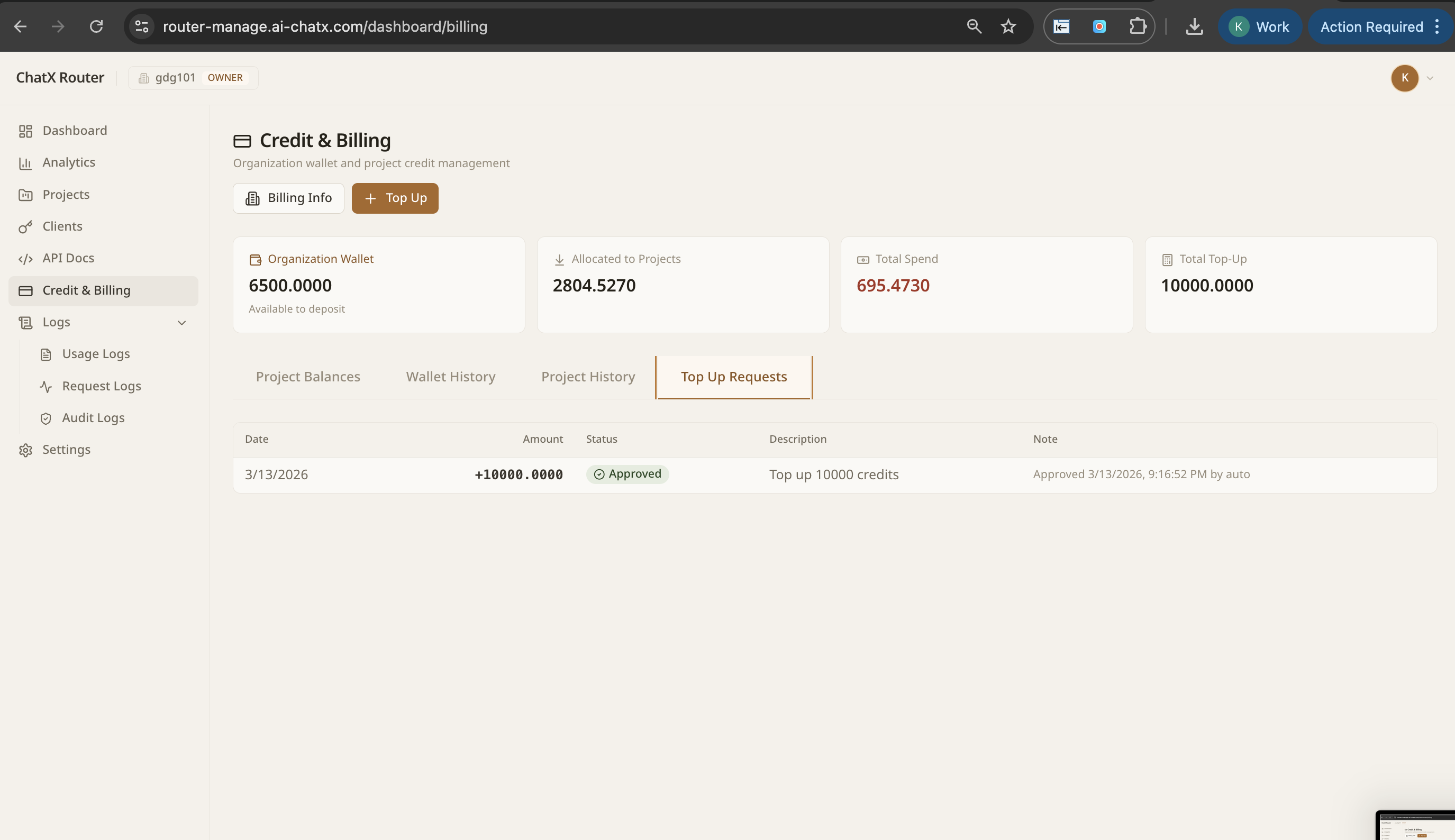
Early Access — 5 enterprises · SEA Q2 2026
The AI Control Plane
for Enterprises
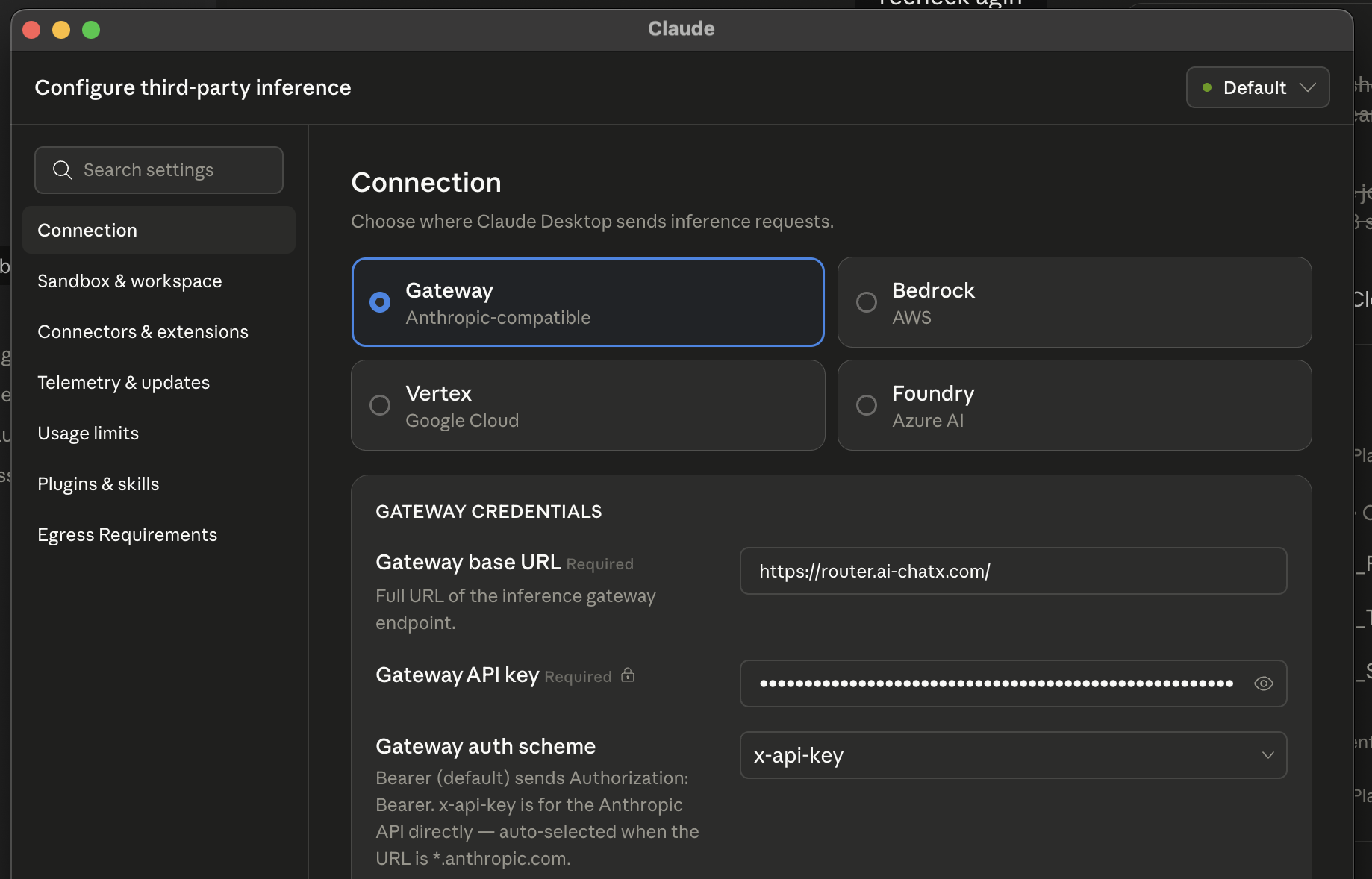
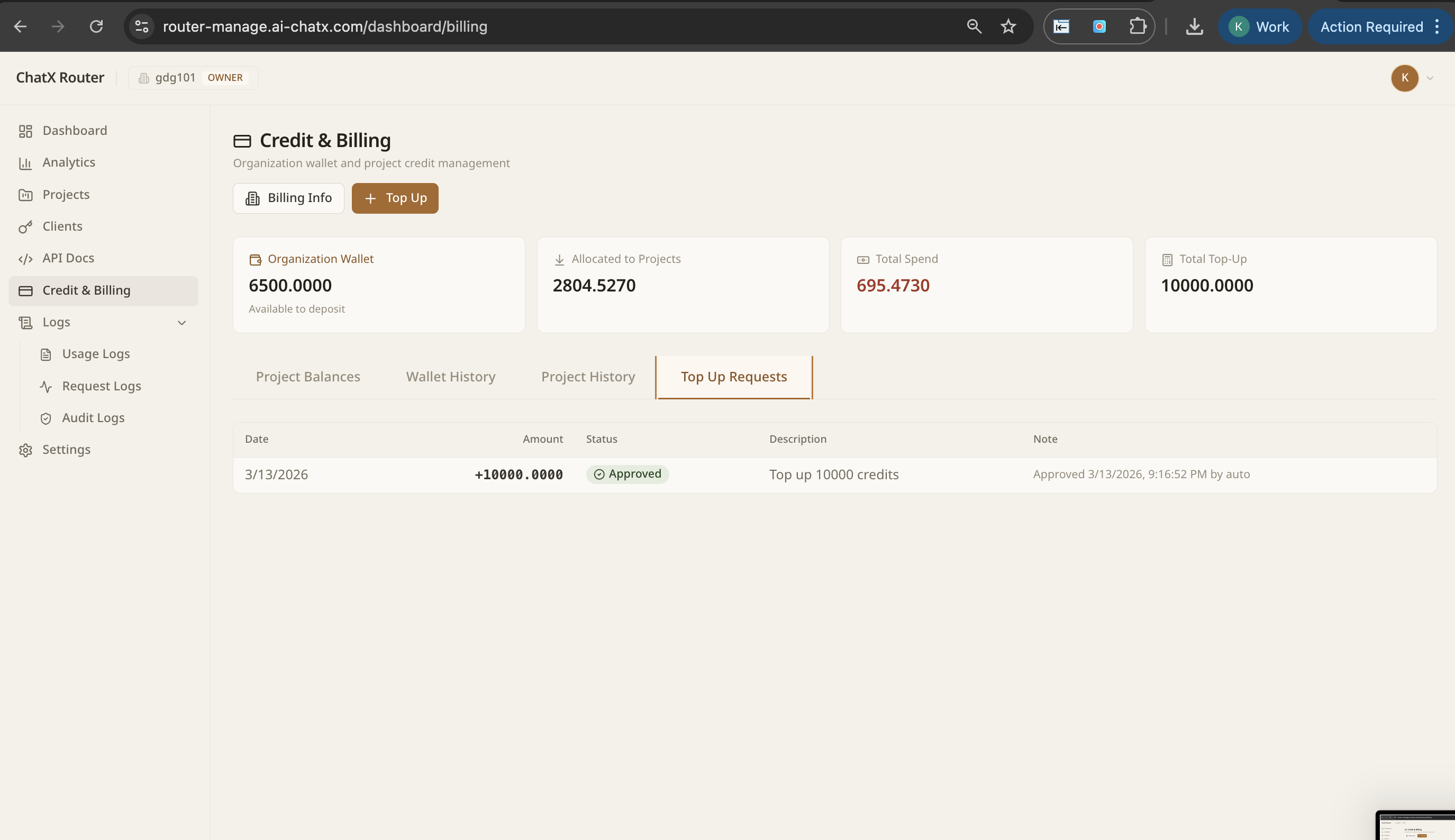
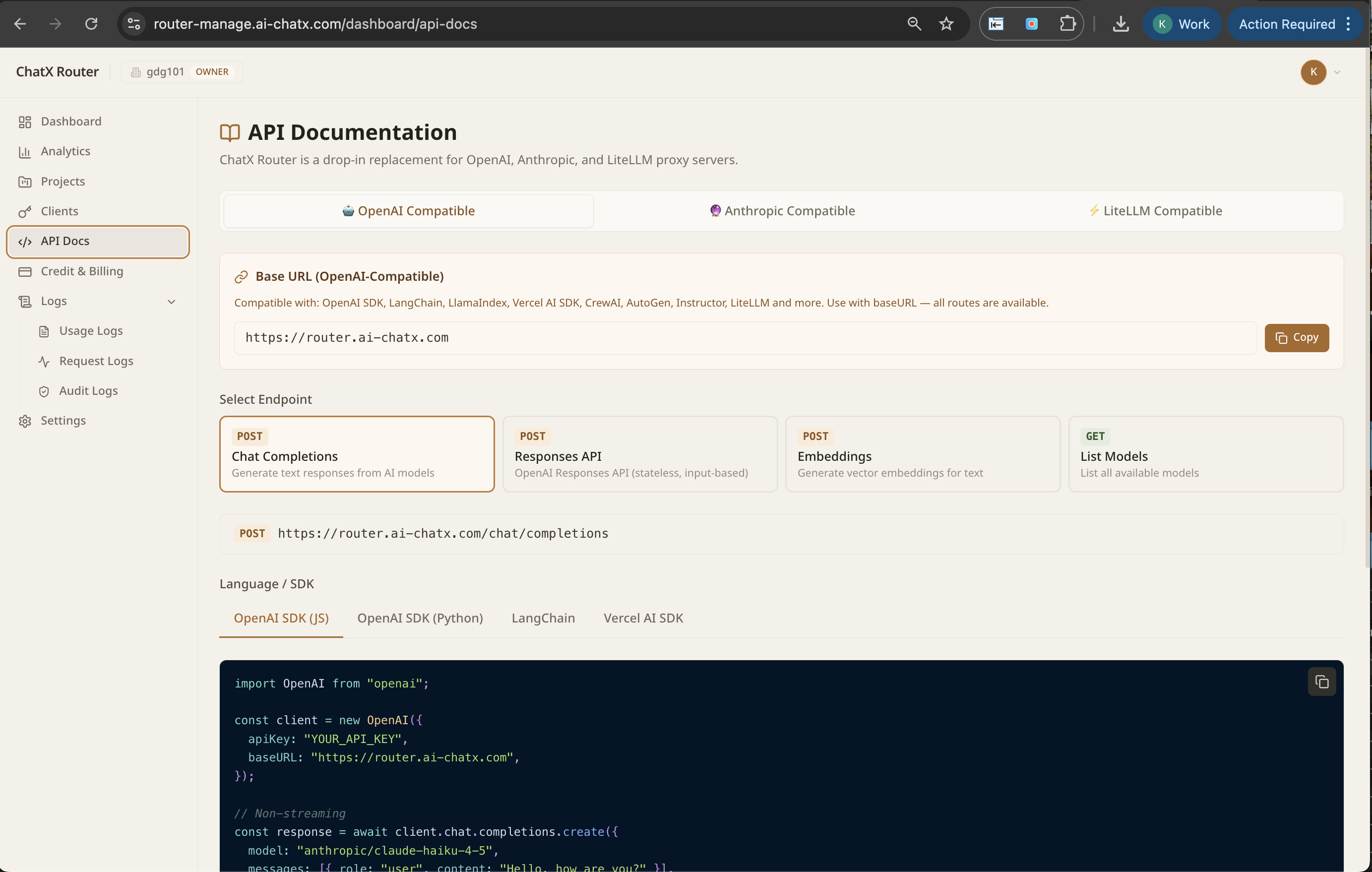
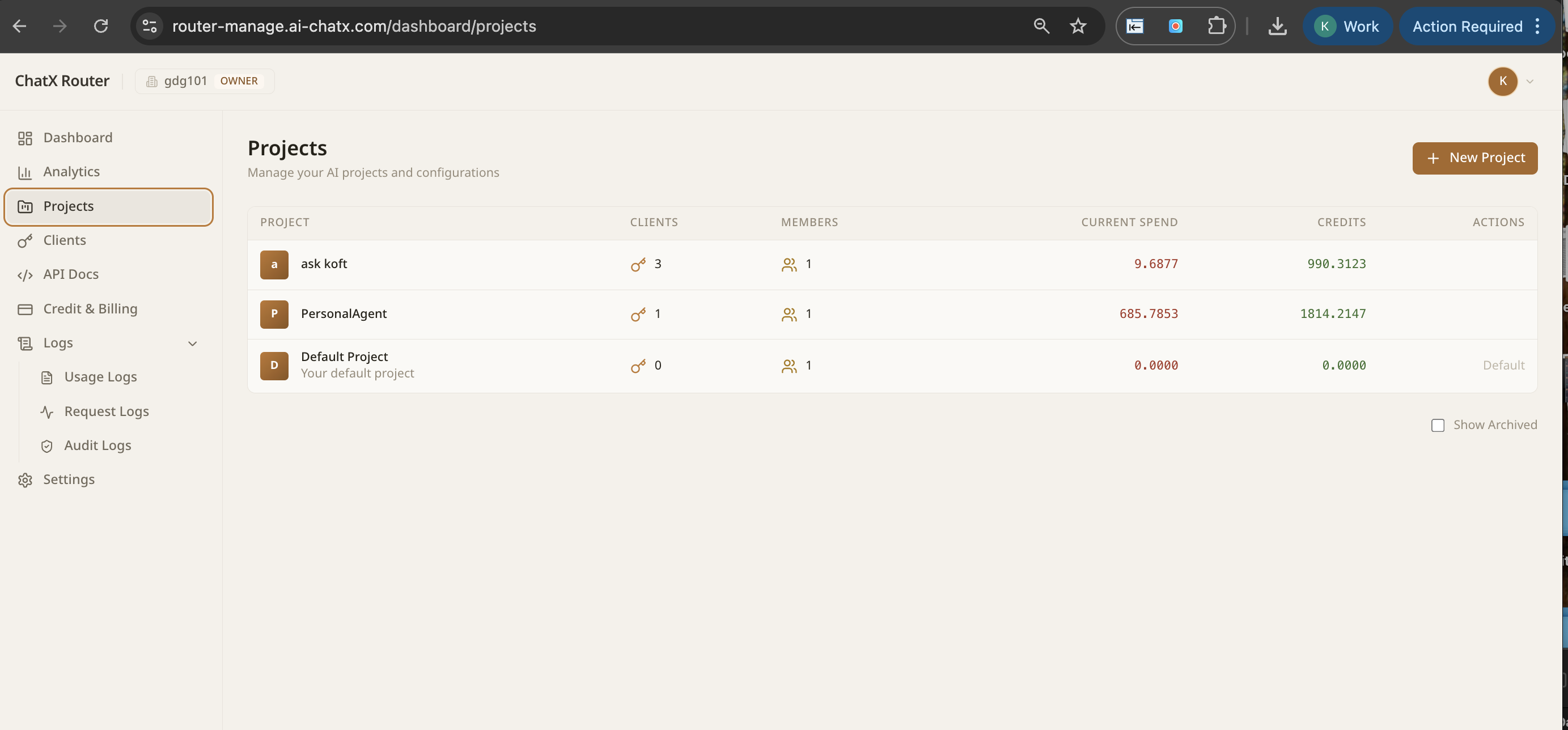
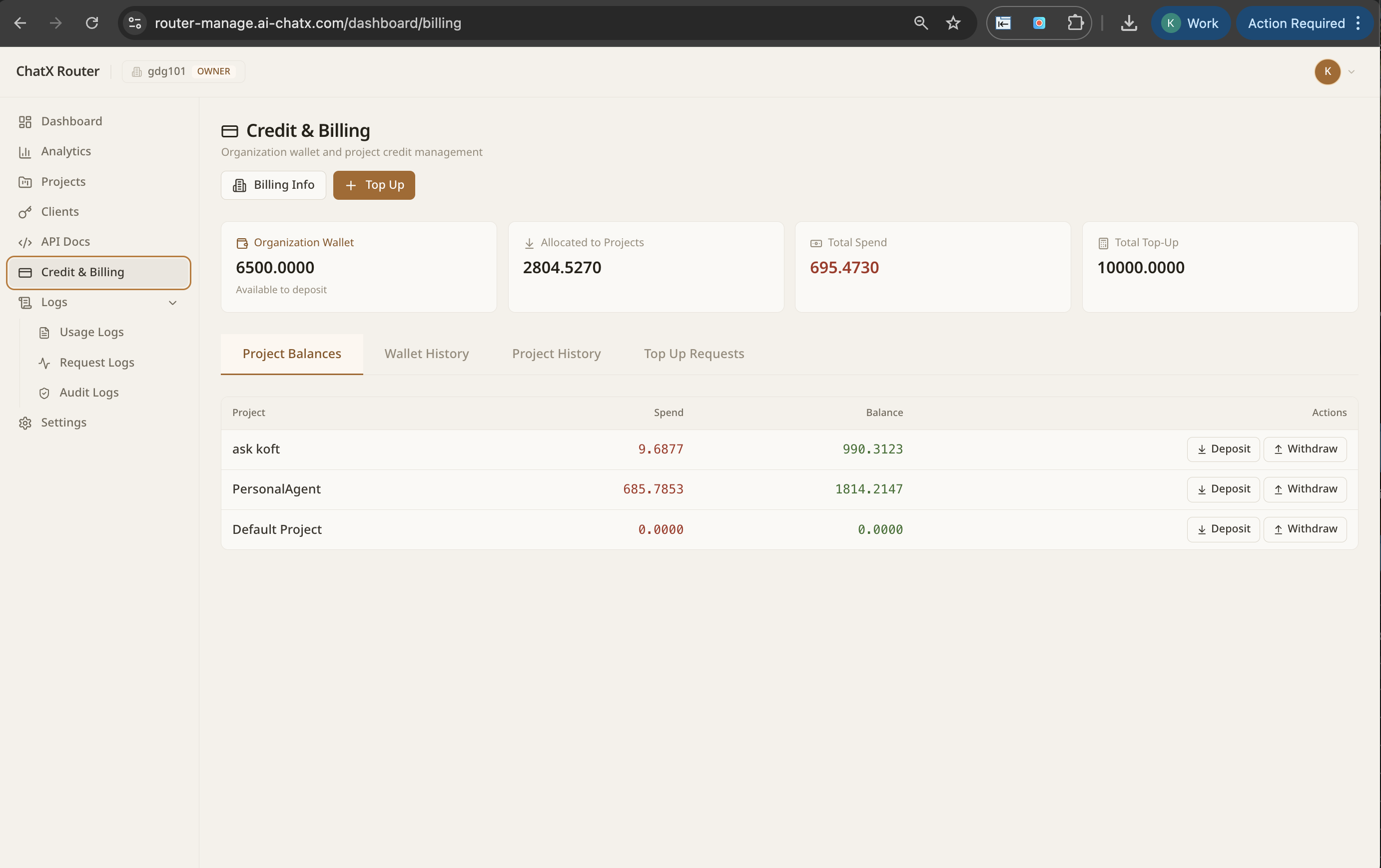
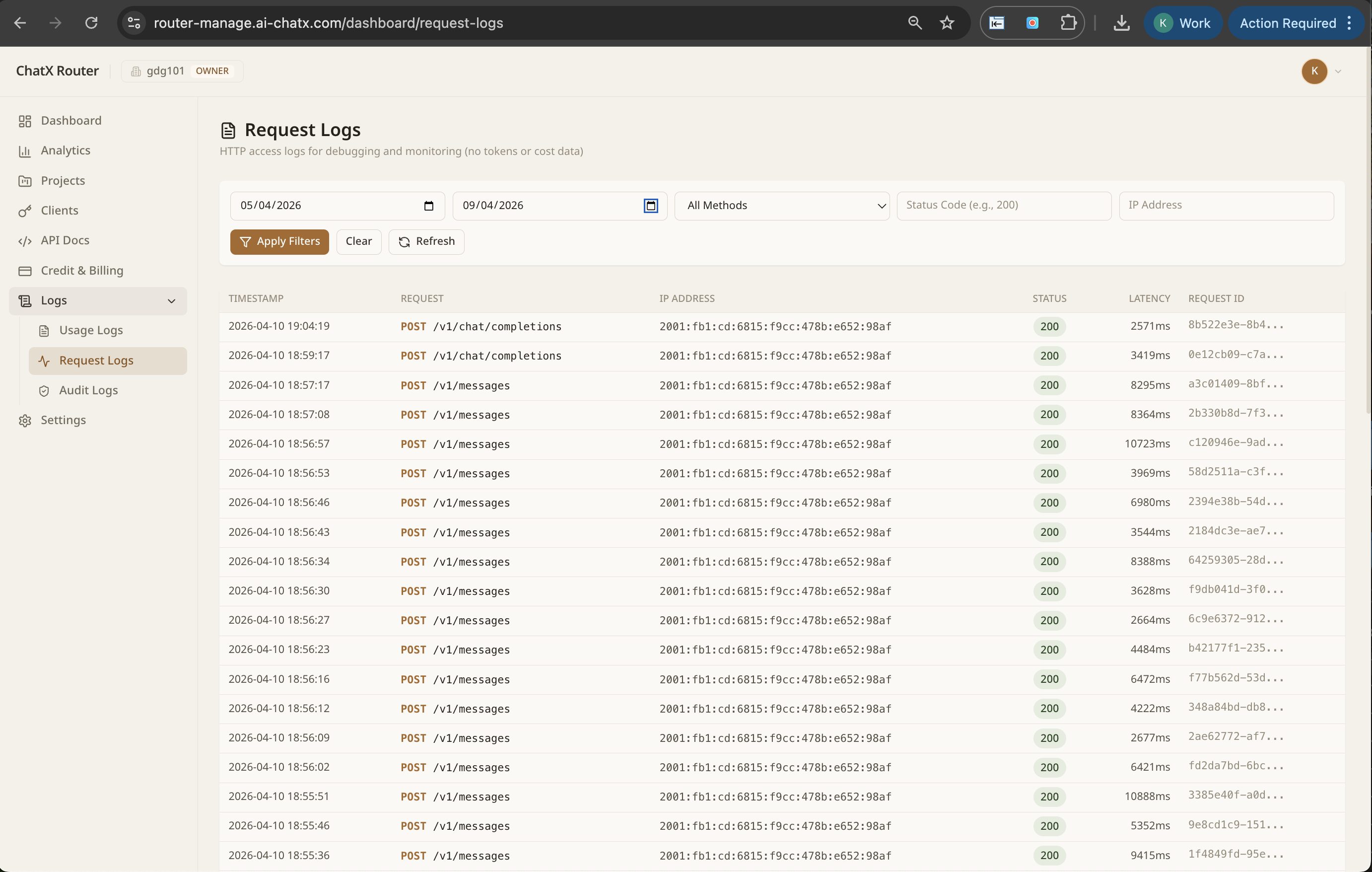
One endpoint, every LLM. NextBrain gives you governance, observability, intelligent routing, and failover across GPT-4, Claude, AWS Bedrock, and your own fine-tuned models.
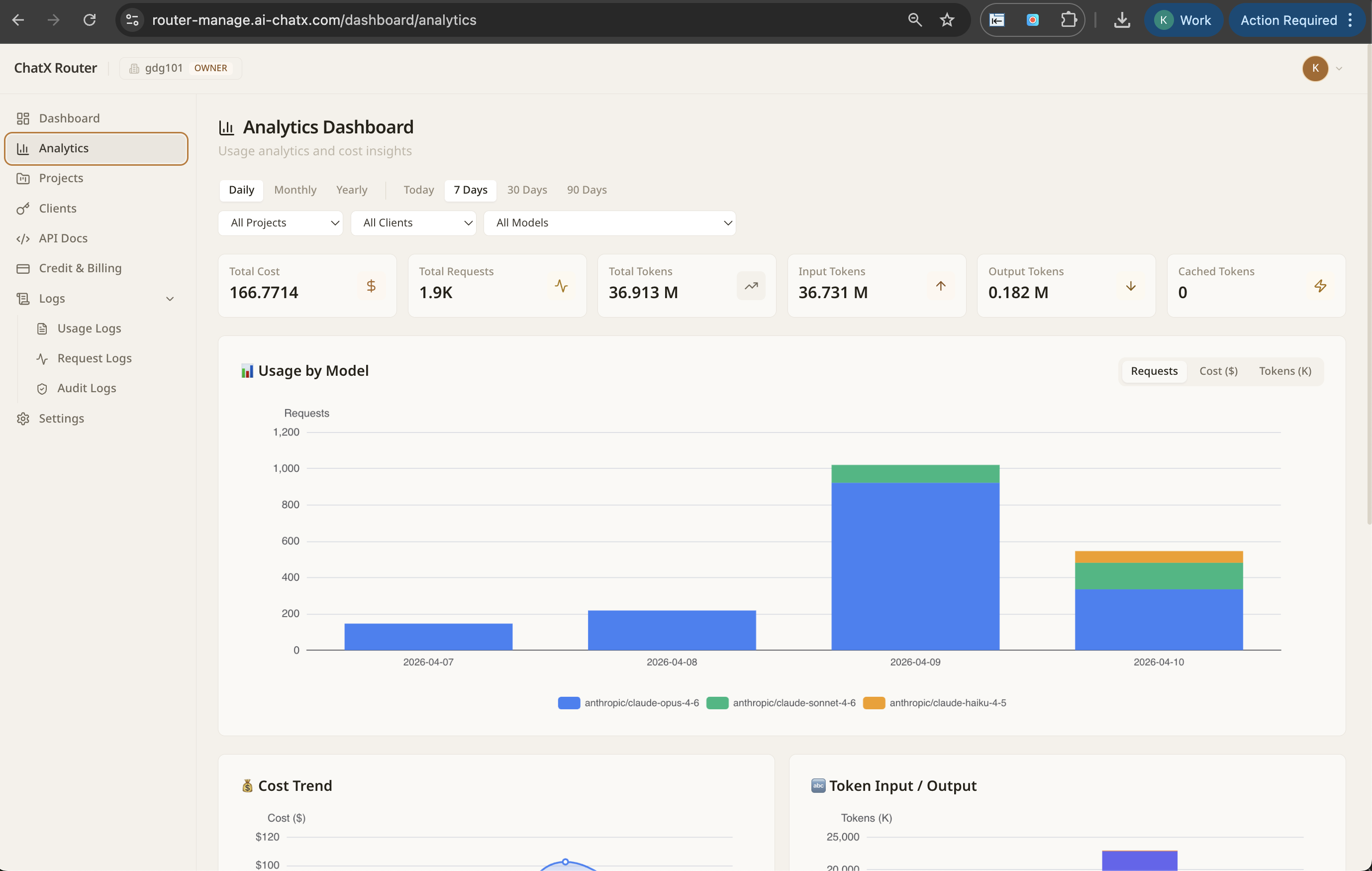
72 models
13 providers
30 min integration
1 endpoint
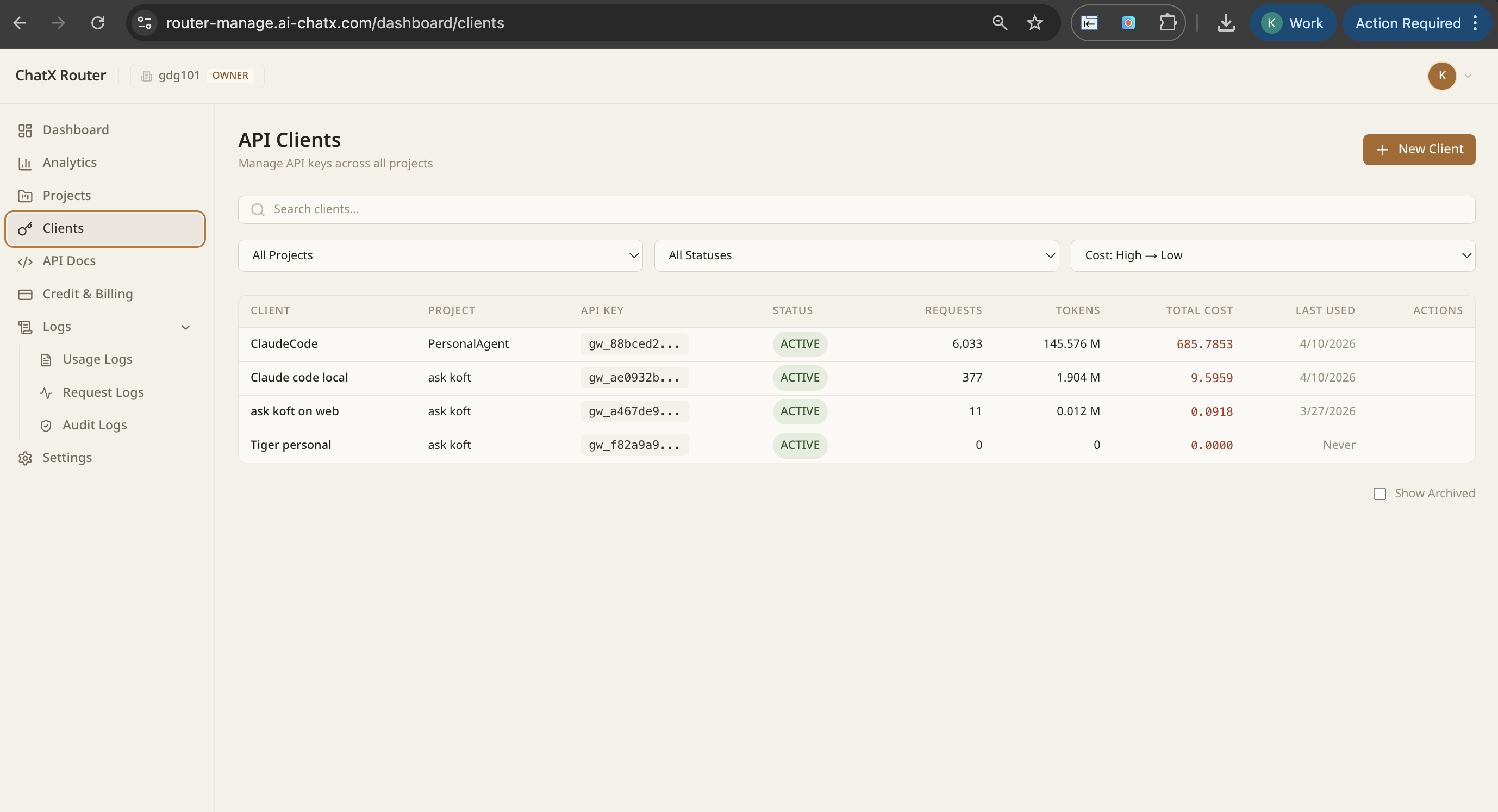
Works with every LLM provider
OpenAI
Anthropic
AWS Bedrock
Google Vertex AI
Azure OpenAI
Self-hosted